During the last years there is a fast growth of machine learning (ML) technologies fuelling artificial intelligence (AI) applications, such as computer vision, automatic speech recognition, natural language processing, and recommender systems. Big Data played a big role in this growth, however, as the modern society is now aware of issues regarding data ownership and data privacy (simply put it, who has the right to use the data generated by a third entity for building AI technologies) the initial approach of gathering and transferring the data to one central location where powerful computers could train and build ML models is no longer valid.
TERMINET acknowledging the data ownership/privacy value in today’s society adopts the Federated Learning (FL) paradigm for being able to train ML models and build domain specific AI applications. Federated Learning is a collaborative machine learning technique allowing multiple distributed edge devices or servers train a shared prediction model using their locally stored data. By moving AI to the edge, FL not only enables the collaboration of computational resources from different processing nodes, but also provides better data privacy, since training data is not transmitted to a central server [1].
Pushing complexity to the edge where the computing resources are usually not as vast as in the Cloud side (and in some cases pretty much constrained) Edge Acceleration paradigm comes at hand. Edge Acceleration can be thought of as boosted Edge Computing (i.e., computing done at or near the source of the data); a state that is achieved by utilizing hardware acceleration paradigms, such as GPU, ASIC and FPGA computation acceleration technologies. Boosted Edge Computing not only enjoys the benefits of reduced latency and of increased privacy and security levels of conventional Edge Computing (no need to transfer, process and/or store data to cloud/central datacenters), but also leverages hardware acceleration in terms of computing speed and/or lower energy consumption. In the light of this TERMINET utilises the FPGA technology to introduce acceleration at the Edge.
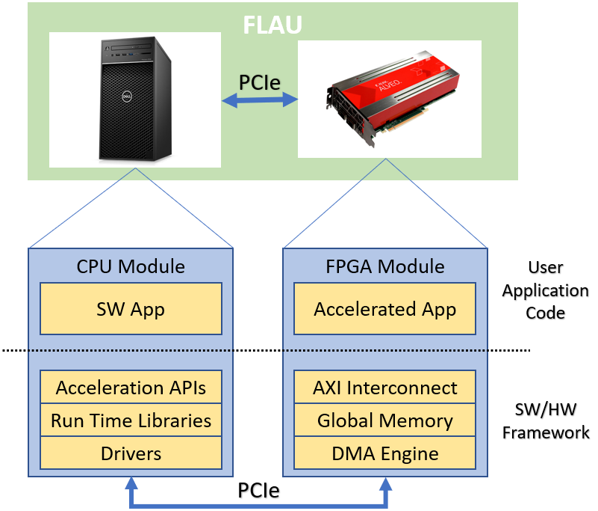
Acceleration in TERMINET was introduced in the form of an FL Acceleration Unit (FLAU), a hardware – software co-design for efficiently accelerating the federated learning machine learning models. This unit leverages the high bandwidth, high density, high performance, and design flexibility offered by FPGAs allowing the efficient implementation of computationally intensive functions (traditionally implemented by means of software) in hardware. As shown in the below figure, the FLAU comprises of two parts:
- the FPGA Module used to implement the HW accelerated functions of federated learning.
- the CPU Module used to facilitate the a) deployment of the accelerated functions to the FPGA Module, b) the forwarding of information to the FPGA for being processed, c) the integration of the FPGA resources into the TERMINET platform and cloud.
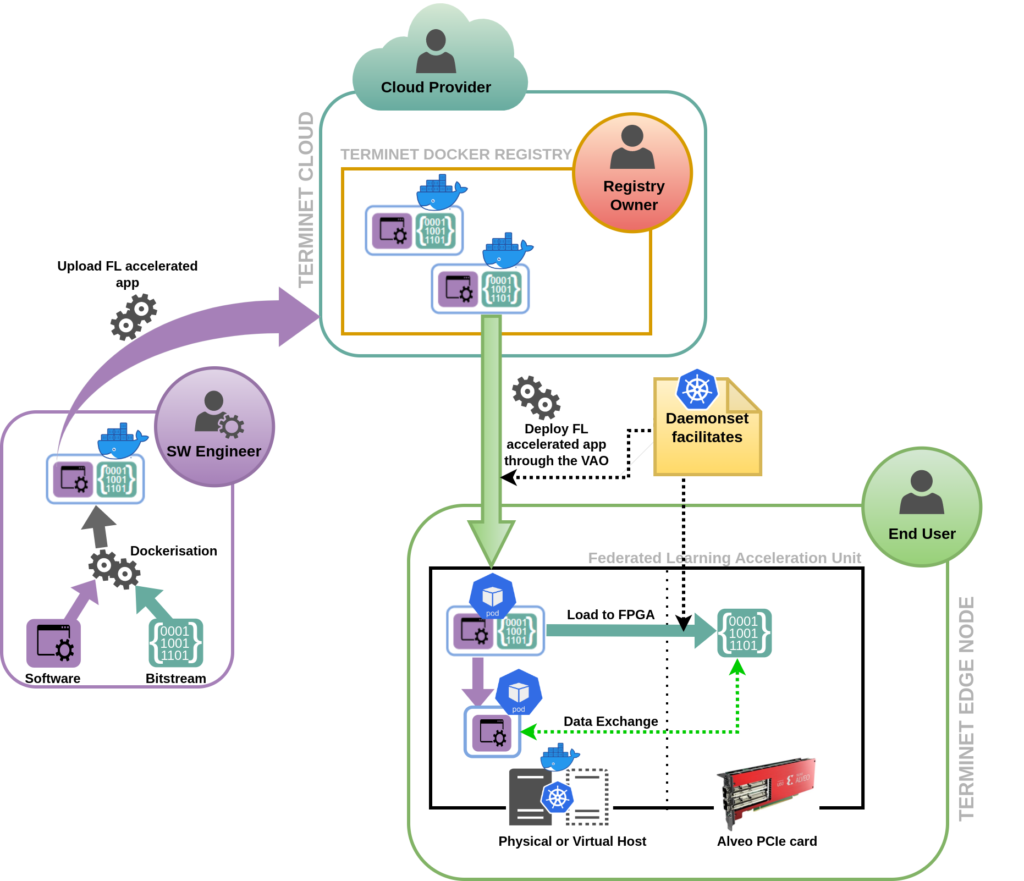
FLAU is integrated in a TERMINET edge node and as such is part of the TERMINET Kubernetes cluster. In this context, VAO (Vertical Application Orchestrator component) can create and manage Kubernetes pods able to run the accelerated ML algorithms; The following figure is a conceptual sketch showing how FPGA accessible Pods are deployed on a FLAU worker node.
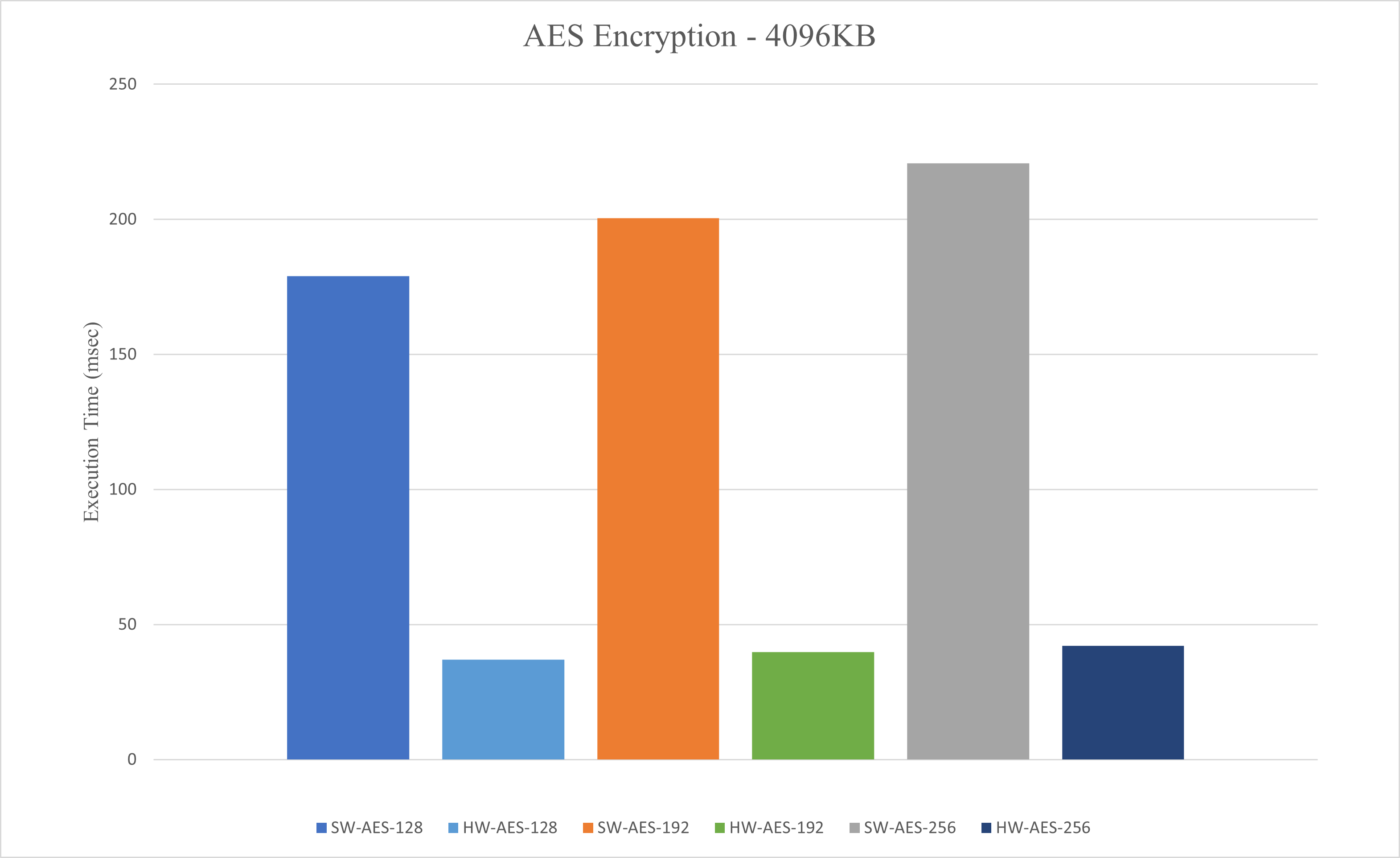
Several performance evaluation scenarios were run to highlight the capacity of the FLAU to speed up computationally intensive tasks like the encryption of information. In such a scenario, the Advanced Encryption Standard (AES) algorithm was implemented in the FPGA module of a selected FLAU; in addition, and for comparison reasons, a software version of the same AES algorithm was implemented for the CPU subsystem of the FLAU. Both versions were fed with the same input for encrypting/decrypting it, namely for the input sizes of 512, 1024, 2048 and 4096 KBytes respectively using three different encryption key lengths, i.e., 128 bits, 192 bits and 256 bits. For space economy only the results of the case with the 4096 KB input size are displayed. Nevertheless, all the performance results revealed the same trend; the accelerated encryption module had a x5 gain for the encryption operation (similar results were observed for the decryption) over the pure software AES version. It is noted here that the gain could be further improved, if we had pushed further for the optimization of the accelerated algorithm, however this was not needed for the proof of concept.
TERMINET driven by the values of experimentation and innovation builds on several concepts and paradigms amongst them the federated learning and edge computing acceleration. In this direction, it introduces a component (Federated Learning Acceleration Unit) that supports the acceleration of complex and computationally intensive FL functions by enabling them to offload their computationally intensive tasks to its FPGA. One of the major advantages of the implemented system is that it can be dynamically add/remove FLAUs to/from TERMINET edge nodes, thus easily scaling up/down FLAU resources as needed to meet changing demand. The acceleration capacity of the implemented system was verified by running a software and an accelerated version of the same AES algorithm showing a x5 performance gain in terms of speed. Over the next period, and as the rest of WP4 progresses, effort will focus on porting FL solutions that will be developed in other WP4 tasks (for the needs of the TERMINET UCs) in respect to FLAU component. This work and the relevant evaluation results will be documented in the upcoming WP4 deliverables. For more details you can refer to the public TERMINET deliverable D4.1- Federated Learning Accelerating Infrastructure.
References:
[1] Q. Xia, W. Ye, Z. Tao, J. Wu, and Q. Li, “A survey of federated learning for edge computing: Research problems and solutions,” High-Confidence Computing, vol. 1, no. 1, p. 100008, Jun. 2021, doi: 10.1016/j.hcc.2021.100008.